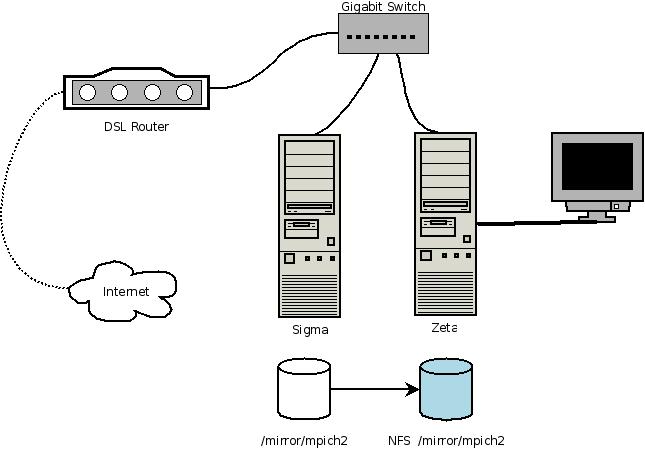
As I mentioned previously, one of the reasons I built another quad-core PC was that I wanted to do some experiments with high performance computing. Even though the idea of a two-node mini cluster does not sound like much, the principle behind it is pretty similar to much larger and more powerful clusters.
Typically a large computer cluster has a single head node and many compute nodes. These nodes are interconnected via a fast dedicated network (e.g. Gigabit Ethernet or Infiniband). The head node typically has two network adapters which bridges the WAN (or Internet) and the cluster.
For a two-node Beowulf cluster setup however, the above requirements (e.g. one head node and many compute nodes) can be greatly relaxed. Particularly in a two node environment, we do not have the luxury of having a dedicated head node and we have to use both nodes as compute nodes in the cluster. As a result, one of the two nodes will be both the head node and the compute node. As you will see later, the difference between the head node and the compute node in a two node cluster is not all that significant. Furthermore, since the cluster sits behind a firewall, there is no need to bridge the head node from the outside world via a second network adapter. The DSL router is sufficient to isolate the LAN from the Internet. This drops the two NIC requirements.
1. Choosing an MPI (Message Passing Interface) package
There are primarily two popular MPI implementations: MPICH and LAM/MPI. Some technical and performance differences exist between these two implementations (you can find more information in this research paper. This link has some high level information). Since MPICH2 implementation relies solely on SSH and does not require a daemon running on each machine in the cluster, it is presumably easier to setup in an environment that involves a large number of nodes. But for my particular setup, either implementation should serve the purpose. I chose to use MPICH2.
2. Setting up the MPI Environment
The two PCs (zeta, sigma) I use for the cluster both have a quad core processor (Q9450) and 8GB of RAM. The hardware configurations are slightly different (one Motherboard is based on Intel X38 chipset and the other one is based on P43) and the OSes are slightly different as well (one is running 64bit Ubuntu 8.04 and the other is running 64bit Ubuntu 8.10). None of these differences are material though.
In my setup, I used zeta (Ubuntu 8.04) as the head node since that is where my primary desktop is on. My new built (sigma, Ubuntu 8.10) runs in headless mode and serves as a compute node.
There is a lot of information on the Internet on how to setup an MPI environment. But most articles are rather dated. For Ubuntu cluster setup, this article is pretty much up-to-date (the article mainly targets Ubuntu 7.04 and there are some places that need to be updated and I will point those out as we move along). Some of the best references on MPI environment setup come from the MPICH2 distribution tar ball:
mpich2-1.0.8/doc/installguide/install.pdfmpich2-1.0.8/doc/userguide/user.pdf
It definitely pays to read them through prior to setting up the environment. There are many useful trouble shooting tips in the installation guide as well, and they will come in handy should you run into any setup issues.
3. Setting up NFS on the Head Node
The installation guide that came with the MPICH2 distribution points out that NFS is not necessarily required for MPICH2 to function, but it would be necessary to duplicate the MPICH2 installation and all the MPI applications in the same directory structure on each node. Things become so much easier if all the nodes can use the same NFS directory where MPICH2 installation and MPI applications are. See Step 2 in the MPICH Cluster article.
4. /etc/hosts, mpd.hosts and SSH Setup
As indicated in the article I mentioned earlier, we need to change /etc/hosts on both nodes to contain the IP addresses of each server.
Pay special attention to the 127.0.1.1 address that points to the server name. For MPICH2 to work properly, this IP address must be changed to the real IP address of that server. For instance, here is the /etc/hosts on zeta:
127.0.0.1 localhost#127.0.1.1 zeta192.168.1.67 zeta192.168.1.68 sigma
And similarly here is the /etc/hosts file on sigma:
127.0.0.1 localhost#127.0.1.1 sigma192.168.1.67 zeta192.168.1.68 sigma
You will also need to create a mpd.hosts file on each of the nodes within the user’s home directory (note, this is the user you wish to run mpi under). Here is my mpd.hosts (I only have two machines in the cluster):
zetasigma
MPICH2 requires trusted SSH among compute nodes and head node. Please see Step 7 in this article I mentioned earlier. Note that in Ubuntu 8.04 and 8.10 the authorized keys file is called authorized_keys2 and the actual keys generated using ssh-keygen by default are id_dsa and id_dsa.pub. It does not really matter what type of keys you choose. Either DSA or RSA should be fine. This step should be repeated on each cluster node and the id_dsa.pub generated on one machine should be added to authorized_keys2 on the other machine. In my setup, I added the id_dsa.pub on zeta to the authorized_keys2 on sigma and vise versa. This is where we make distinction between head node and compute nodes. Since head node needs to communicate with all the compute nodes, it needs to have all compute nodes’ public keys. Whereas each compute node only needs to have the head node’s public key. As you can see, in a two-node scenario, either node can be used as the head node.
5 Building and Installing MPICH2
The MPICH Cluster article on Ubuntu documentation has some great details on this so I am not going to repeat here. One thing you need to pay special attention is the .mpd.conf file (located in user’s home directory).
This file is used to make the communications among cluster nodes more secure. To ensure that computers within the same cluster can communicate with each other, each machine must have the same secret word. If the secret word does not match, you will receive a handle_mpd_output error (e.g. failed to handshake with mpd on <node name>; recvd output={})
6 Test Run
On zeta (head node) export the NFS node
exportfs -a
On sigma (compute node) mount the NFS exported from zeta on the same path so that the directory structures on both machines are the same.
sudo mount zeta:/mirror /mirror
On zeta (head node) start up the mpd on both nodes according to mpd.hosts
mpdboot -n 2
Right now running mpdtrace on either machine you should see both nodes get listed.
Running the interactive version of cpi on one core with an interval number of 100,000,000
mpiexec -n 1 ./icpi
it took 1.93 second to complete.
Running with all 8 cores with the same paramter:
mpiexec -n 8 ./icip
took only 0.31 second which is more than 6 times faster than the signle core version.
The following figure recaps the structure of my cluster setup: